llms.txt File: Get Cited by ChatGPT, Claude & Perplexity
llms.txt file is a markdown-based governance document placed at the root of a website to provide large language models with a clean, heavily curated summary of the site's most important pages, identity, and documentation. This structured layer helps generative agents bypass cluttered HTML to extract accurate, verifiable brand information.
The transition from traditional algorithm optimization to generative search has forced brands to adopt new technical standards. Search engines index web pages for human consumption, but AI agents require machine-readable frameworks to operate efficiently. Providing a clean data set reduces hallucinations and ensures your brand narrative remains intact.
Strategic deployment of these files allows organizations to explicitly state their core competencies to language models. When automated web crawlers seek context, offering a focused text file prevents them from pulling outdated or irrelevant content from your site hierarchy. This is the foundation of structural brand authority in the modern web architecture.
Key Takeaways
- Early adoption remains niche. An analysis of 137,000 domains by Ahrefs found that only 28% had published this specific file at their root.
- Formatting standards rely on brevity. The official specification maintained by AI Visibility informal guidelines recommend keeping the text document under 50 KB to maximize efficient model consumption.
- Bots dominate current file access. Within the domains successfully hosting the standard, 96% of all file requests originated strictly from automated web agents rather than human browsers.
- Citation correlation is currently nonexistent. Extensive testing across 300,000 global domains revealed no measurable increase in AI engine citations directly tied to hosting the file — a pattern that mirrors our own AI Citation Gap Study, where 5,400 prompts across ChatGPT, Gemini, Claude, and Perplexity showed citation share is driven by earned authority, not file-level signals.
- Structure mitigates model hallucination risk. Directly serving markdown-formatted summaries to retrieval-augmented generation systems prevents bots from stripping crucial context from deeply nested site pages.
What exactly role does an llms.txt file serve?
This document acts as a highly specialized map designed specifically for retrieval-augmented generation (RAG) systems and AI agents. It distills complex corporate websites down to their factual essence.
Standard website architecture relies heavily on CSS, JavaScript, and nested HTML tags. While this renders beautifully for human readers, it creates unnecessary noise for language models. An llms.txt file strips away this clutter, serving only the structured information that a cognitive engine needs to understand your brand.
By relying on markdown syntax, companies can outline their core services, leadership structure, and key product documentation. This reduces the compute cost for models like ChatGPT or Claude when they attempt to parse your domain. A clear, static file gives you a direct line to the model's contextual understanding.
Many brands use this infrastructure as a defensive measure. When AI entities read your site without explicit guidance, they may prioritize outdated press releases or peripheral blog posts over your main value proposition. The file forces the crawler to acknowledge your defined reality.
Implementing this technical layer sits squarely at the intersection of developer operations and brand communication. You are essentially building an API endpoint for crawler understanding. For an extensive look at how these pieces fit into broader visibility, consult our detailed llms.txt Guide.
Does an llms.txt file actually guarantee indexing?
The presence of this document does not automatically force generative engines to cite your brand or index your content favorably. It is a governance mechanism, not a magic ranking signal.
Industry data paints a sobering picture of current utilization. A massive study by SE Ranking analyzed nearly 300,000 domains and found that only 10.13% had adopted the standard. More importantly, their tests showed no observable increase in AI citations for domains using the file compared to those without it.
This lack of immediate citation boost aligns with findings from other industry monitors. Search Engine Land tracked the implementation across ten websites. Only two sites experienced any increase in AI-driven traffic, but the analysts concluded those gains were driven by broader content efforts, completely unconnected to the text file itself.
Despite the lack of direct ranking correlation, major platforms are taking notice of the infrastructure. The Wix Studio AI Search Lab reports that Google currently indexes between 30,000 and 60,000 of these files globally. Engines are cataloging the data, even if they are not heavily weighting it yet.
"Treat machine-readable files as a foundation for brand accuracy, not a shortcut for immediate search traffic. Supplying clean data minimizes the risk of AI hallucinating your core offerings."
This dynamic reinforces the reality that true visibility requires both structural clarity and earned authority. You map the site for the AI, but you still need trusted third-party validation to prompt the model to care about you. This is why a cohesive PR & Media Services strategy must run parallel to technical optimization.
How does an llms.txt file compare to robots directives?
Understanding the distinction between legacy web crawlers commands and modern generative engine mapping is vital for technical marketing teams.
A robots.txt file is entirely restrictive. It tells search engine crawlers which directories they are forbidden from indexing. A sitemap.xml file is purely navigational, offering a sprawling list of internal URLs without qualitative context about what those pages mean.
The llms file bridges this gap by acting as a curated, qualitative summary. Instead of just listing links, it explicitly defines the brand, highlights the most critical documentation, and provides high-level narrative context. It instructs the agent on *what* to understand, rather than just *where* to go.
| Technical Asset | Primary Function | AI Agent Utility |
|---|---|---|
| robots.txt | Restricts crawler access to specific paths. | Prevents model ingestion of private data. |
| sitemap.xml | Provides a comprehensive inventory of all URLs. | Offers raw discovery without narrative priority. |
| llms.txt | Delivers a machine-readable narrative summary. | Guides contextual understanding and RAG mapping. |
| Schema Markup | Categorizes specific page-level entity types. | Validates organizational facts and product details. |
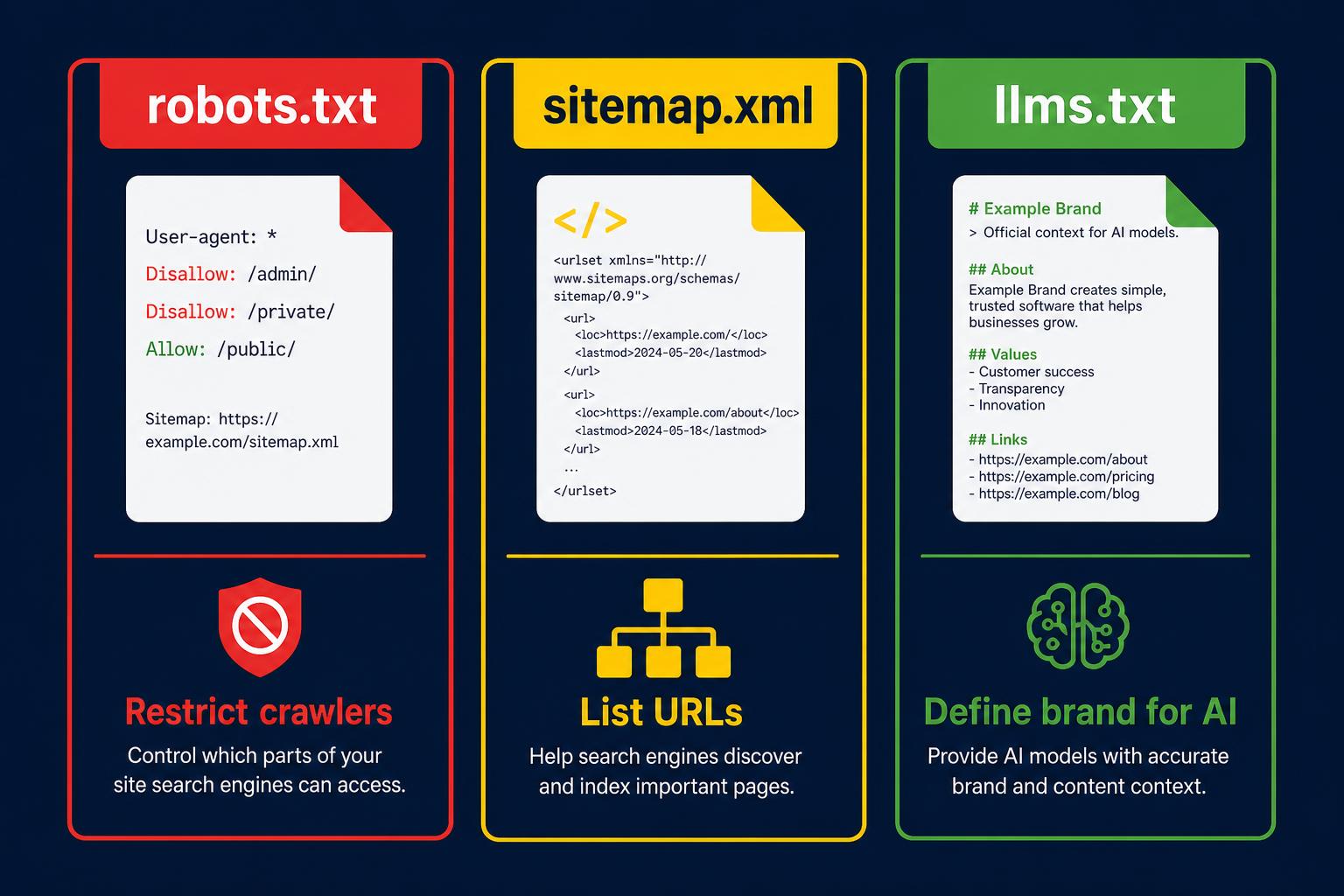 robots.txt restricts crawlers, sitemap.xml lists URLs, llms.txt defines brand context for AI agents.
robots.txt restricts crawlers, sitemap.xml lists URLs, llms.txt defines brand context for AI agents.
These assets do not compete; they stack. A sophisticated technical stack uses robots constraints to block scrapers, schema markup to validate entities, and the markdown file to provide the overarching brand thesis. Missing any of these layers leaves your brand vulnerable to misinterpretation.
When engineering these systems, marketing leaders often confuse permission with preference. Granting an AI permission to read your site via robots directives is not the same as giving it a preferred reading list. For more insight on harmonizing these elements, review the Answer Engine Optimization Guide.
What structural components should be inside the file?
Crafting an effective markdown summary requires balancing comprehensive detail with extreme brevity. Language models drop context when forced to parse oversized documents.
The primary section must contain the brand name, a definitive statement of purpose, and the core value proposition. This opening paragraph serves as the atomic unit of your brand identity. If a model truncates the file, this foundational definition must survive intact.
Following the brand definition, implement a strictly curated link section. Do not dump your entire navigation menu here. Focus exclusively on authoritative touchpoints: deep documentation, peer-reviewed whitepapers, transparent pricing logic, and leadership bios. The goal is signal, not noise.
The organization AI Visibility maintains the v1.7.0 specification for this standard. They strongly recommend keeping the overall document size beneath 50 KB, which equates to roughly 100 lines of highly efficient markdown text. Bloat destroys utility in agentic workflows.
It is also crucial to include an "Optional" flag for auxiliary links. By structuring secondary information logically, you allow the parsing agent to decide whether it requires deeper exploration based on the user's specific prompt. Learn more about file optimization in our llms.txt generator guide.
Who is actually crawling and reading this markup?
Understanding the audience for your technical governance documents requires a clear look at server log data. The traffic patterns differ wildly from traditional web browsing.
Human interaction with these governance files is virtually nonexistent. Ahrefs research showed that of the small number of files actually accessed, 96% of requests came directly from automated bots. You are strictly writing for software, requiring a different linguistic approach.
The bots accessing these documents fall into specific categories. Within the same Ahrefs dataset, 19.5% of successful fetches originated from clearly named AI tools, most notably GPTBot and Claude-Code. These proprietary scrapers actively look for structured onboarding materials when ingesting domain data.
If You're Invisible in AI, You're Losing Clients Right Now.
See exactly how your company appears across AI, search, and investor research — and uncover the hidden gaps costing you trust and deals.
Another 12% of the crawler traffic originated from technical auditing tools, standard checkers, and researchers analyzing the adoption rate of the specification itself. This indicates an ecosystem in its infancy, where tools are building the capacity to read the standard before end-user applications fully weaponize it.
It is important to note that traditional search infrastructure treats this asset neutrally. Yotpo emphasizes that Google currently ignores the file when calculating traditional ranking positions. The file exists solely to assist autonomous data extraction, not to game legacy search engine result pages.
How can marketing teams automate file generation?
Manual curation of specialized markdown files becomes unsustainable for enterprise domains with rapidly shifting product catalogs. Automation bridges the gap between static governance and dynamic website updates.
Using an llms.txt generator simplifies initial deployment. These tools parse existing sitemap structures, extract primary H1 headers and meta descriptions, and compile them into a unified markdown format. This base layer gets you past the blank-page problem immediately.
Advanced engineering teams integrate generation scripts directly into their deployment pipelines. Using GitHub Actions or Python scripts, the system can automatically rewrite the file every time a core documentation page is altered. This ensures the language model never receives a dead link.
Before pushing any automated file to a live production environment, technical leads must run the output through a rigorous llms.txt validator tool. A validator checks for broken markdown syntax, ensures the file remains under the critical 50 KB threshold, and verifies URL accessibility.
Relying purely on automation can sometimes strip the nuanced brand narrative. It is highly recommended that a human editor review the top-level brand definition quarterly. For best practices on establishing these workflows, explore how technical infrastructure intertwines with our Generative Engine Optimization Guide.
What security and prompt injection risks exist here?
Exposing a curated blueprint of your most valuable data to autonomous agents introduces novel security considerations that traditional SEO teams rarely encounter.
When you provide a structured map for integration into RAG architectures, you increase the likelihood that external entities will ingest your proprietary data exactly as written. If your markdown file contains un-gated links to beta pricing or sensitive internal endpoints, language models will cheerfully expose them to end users.
A more insidious threat involves indirect prompt injection. If an attacker manages to inject malicious instructions into a public-facing page that is explicitly highlighted in your markdown file, the AI agent reading that file might execute the rogue instructions when synthesizing your brand data.
To mitigate this risk, maintain strict sanitization protocols. The file must never include raw user-generated content, open comment sections, or untested dynamic URLs. Every link provided to the autonomous system must point to thoroughly vetted, permanently static organizational truth.
"Generative engine optimization requires defensive architecture. Curating your site for an AI agent means strictly gating the information you provide, ensuring no malicious or outdated inputs can poison the model's understanding."
This is why treating the file as a casual SEO experiment is dangerous. It is a binding governance document. Maintaining high Editorial Standards across your linked documentation is your primary defense against agentic hallucination or active data poisoning.
Who should own the llms.txt file strategy internally?
Navigating the convergence of technical engineering and narrative public relations creates organizational friction. Determining ownership of AI crawler communication is a critical modern management challenge.
Historically, technical SEO teams controlled server-root files. However, the markdown summary is qualitative, not quantitive. It relies on precise language, brand positioning, and curated messaging—skillsets typically residing in the communications or product marketing departments.
The ideal structure is a shared governance model. Engineering handles the pipeline integration, ensuring the file remains valid, lightweight, and accessible at the server level. They monitor the bot traffic and report on fetch frequency from major foundation models.
Meanwhile, the PR and strategic communications teams own the actual text payload. They dictate the brand definition and select which high-trust assets are worthy of ingestion. If an executive requires personal reputation management, the communication team ensures those specific verified assets take precedence in the file structure.
Updating the file must be treated like updating a press kit. An outdated media kit damages brand credibility; an outdated text file damages algorithmic understanding. To see how these communication channels align, read about technical optimization for AI visibility and citations.
Will this framework replace traditional optimization?
Adopting specialized AI mapping protocols does not eliminate the need for foundational search and authority-building strategies. They are parallel tracks in a comprehensive digital architecture.
Technical compliance ensures your brand can be understood, but earned authority dictates whether your brand will be recommended. An AI agent might read your markdown file flawlessly, but if trusted third-party publications never mention your company, the model will not serve your brand natively in complex competitive queries.
Current data supports this reality. Having the file does not catapult unknown brands into high-visibility AI Overviews. It simply prevents established brands from being misrepresented when the engine inevitably crawls them. Structural clarity is a prerequisite for success, not the final destination.
Investing in comprehensive zero-click marketing involves both defining your assets clearly and earning the necessary tier-1 media placements that models use to verify trust. You must build the map, but you also must give the engine a compelling reason to follow it.
For brands ready to synchronize their technical infrastructure with their editorial positioning, achieving true zero-click visibility is a deliberate process. Contact Us to evaluate your current generative search posture and align your brand for the modern discovery landscape.
Ready to Build Authority That AI Actually Cites?
Our Authority Buildout Program handles media placements, schema, executive branding, and AI citation signals — so your brand becomes the answer.
People Also Ask
What is an llms.txt file?
It is a structured markdown document placed at the root of a website to help AI models and RAG systems quickly understand the domain's purpose. It contains concise brand summaries and prioritized links to critical documentation, bypassing cluttered HTML. This file acts as a qualitative guide for autonomous web agents.
How to create an llms.txt file?
Creation begins by outlining your core brand definition and gathering links to your highest-value pages using standard markdown syntax. The file should be saved in plain text format and uploaded directly to the root directory of your web server. It is recommended to use automation tools or generators to validate the formatting before publishing.
What should be in an llms.txt file?
The document must include a definitive brand summary, explicit details about core services, and direct links to essential documentation. It should strictly avoid un-gated beta pages, user-generated content, or excessive peripheral links. The total file size should ideally remain under 50 kilobytes to ensure efficient processing by language models.
Do LLM.txt files work?
They are highly effective at providing structured, readable data to AI agents, which helps reduce model hallucination regarding a specific brand. However, current industry research shows they do not act as an immediate SEO ranking factor or artificially boost citations. They work as essential governance infrastructure rather than a shortcut for traffic.
Frequently Asked Questions
Why does a website need this specific AI file?
It provides a machine-readable summary of your website, helping AI agents understand your core brand identity without parsing messy HTML. This reduces the chance of language models hallucinating your capabilities.
Does publishing this file directly improve Google rankings?
No. Current industry data indicates that search engines ignore it for ranking purposes. It exists strictly for RAG systems and generative bots.
What format is required for the text document?
It uses standard markdown format. You include a concise paragraph defining your business, followed by structured links to primary documentation and core service pages.
Should marketing or engineering teams write this file?
While automation tools can parse sitemaps to create a draft, human editing is vital. A PR or marketing lead should review the brand definition to ensure total narrative accuracy.
What links should be excluded from the file structure?
You should leave out raw user-generated content, outdated press releases, and peripheral blog posts. Only include vetted, high-trust assets to prevent AI confusion.
If You're Invisible in AI, You're Losing Clients Right Now.
See exactly how your company appears across AI, search, and investor research — and uncover the hidden gaps costing you trust and deals.
Get insights like this in your inbox
Subscribe for weekly PR strategy, media insights, and actionable tips.
Related Articles
llms.txt Generator: The Complete Guide for AI Visibility
Are generative AI engines actually reading your content? Learn how an llms.txt generator structures data and whether it improves your brand's visibility.
B2B Thought Leadership: Your Brand's Operating System
Most B2B marketing targets the 5% of buyers ready today. B2B thought leadership is the operating system for capturing the other 95% by building trust and authority before they even enter the buying cycle. Learn the framework.
How to Use Semantic SEO for Brand Authority Building
Learn how to use semantic seo for brand authority building to dominate search results, win AI overviews, and establish topical relevance in an AI-driven era.